Abstract
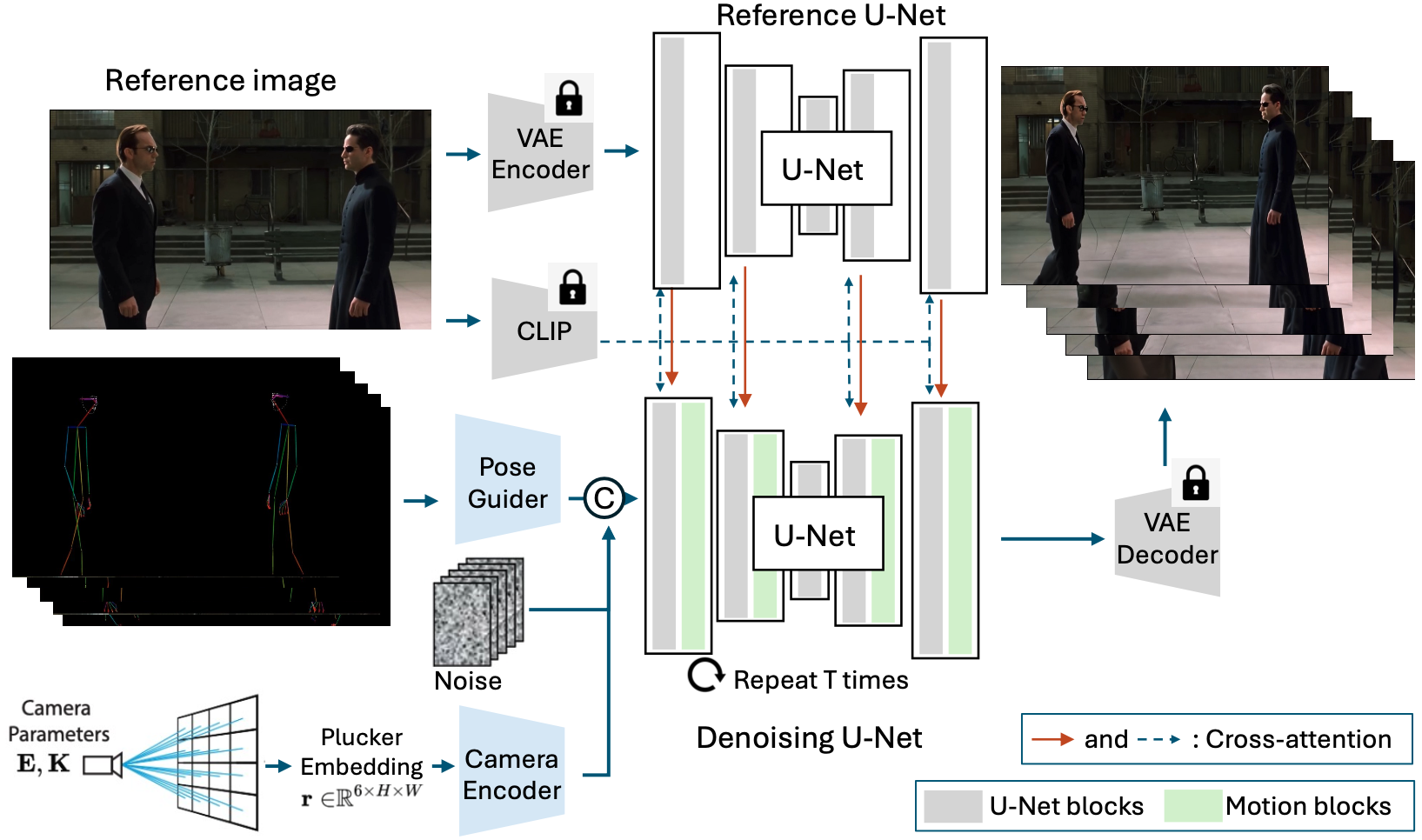
Human image animation involves generating videos from a character photo, allowing user control and unlocking potential for video and movie production. While recent approaches yield impressive results using high-quality training data, the inaccessibility of these datasets hampers fair and transparent benchmarking. Moreover, these approaches prioritize 2D human motion and overlook the significance of camera motions in videos, leading to limited control and unstable video generation.To demystify the training data, we present HumanVid, the first large-scale high-quality dataset tailored for human image animation, which combines crafted real-world and synthetic data. For the real-world data, we compile a vast collection of copyright-free real-world videos from the internet. Through a carefully designed rule-based filtering strategy, we ensure the inclusion of high-quality videos, resulting in a collection of 20K human-centric videos in 1080P resolution. Human and camera motion annotation is accomplished using a 2D pose estimator and a SLAM-based method. For the synthetic data, we gather 2,300 copyright-free 3D avatar assets to augment existing available 3D assets. Notably, we introduce a rule-based camera trajectory generation method, enabling the synthetic pipeline to incorporate diverse and precise camera motion annotation, which can rarely be found in real-world data. To verify the effectiveness of HumanVid, we establish a baseline model named CamAnimate, short for Camera-controllable Human Animation, that considers both human and camera motions as conditions. Through extensive experimentation, we demonstrate that such simple baseline training on our HumanVid achieves state-of-the-art performance in controlling both human pose and camera motions, setting a new benchmark.
Should you have any enquiries, please contact the first author.